GraphQL at Redbox
Posted by InterVenture on April 14, 2021
At Redbox, we are continuously working on improving our platform to deliver the best experience for our customers. In the past year, we have launched many new offerings for our customers such as Free Live TV, Free On Demand movies, completely overhauled TV/Device Apps, Contactless Mobile Pass, and many more. Behind all these exciting customer facing features are many improvements behind the scenes to our platform. From building a multi-region highly available platform from scratch to solving large data problems at scale,
As we continued our journey of digital transformation (modernizing our platform) — Redbox On Demand — we are constantly looking ahead and making sure we are building an extensible and performant platform. As part of this effort, we decided to move from traditional RESTful APIs to using GraphQL as a façade for the backend; facilitating client application development and backend changes.
What is GraphQL?
GraphQL is a query language for your APIs and a server-side runtime for executing queries by using a type system you define for your data. GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data.
GraphQL (https://graphql.org/) has grown in last few years into a well-known technology used to simplify development of applications using some backend. It is now being used by companies that expose large datasets/systems for integrations by client applications; such as Facebook and GitHub.
At Redbox, GraphQL was first used to migrate off our legacy platform hosted by another provider. As mentioned in the past, Redbox On Demand was rewritten from the ground up to enable us to build and grow our own streaming platform. We needed to create new APIs without impacting our customers using the platform. By using GraphQL, we were able to create a backward-compatible API layer that serviced both our legacy platform yet enabled us to flip over to our new platform seamlessly with no impact to our systems, but more importantly our users. It is quickly becoming the main interface for various APIs and data used by Redbox applications for CE and mobile devices.
Why GraphQL?
GraphQL was invented with an idea to solve some of the struggles associated with the use of classical REST services by clients. Problems that client development usually had with RESTful services:
- Resource based APIs where the breakdown of resources was defined statically, not aligned with the client use.
- Resources contain data that might or might not be needed by specific client; data is transferred always.
- To get a larger graph of interconnected resources clients need to execute multiple or many requests adding a large overhead both to client device and the server.
In contrast, GraphQL offers a systematic way of enabling clients to get the structure they want with data they want, in one request. GraphQL exposes a schema showing:
- Which objects are available, and their hierarchy (products, devices, pricing…)
- Which fields are available in objects and their types (supporting built-in types, custom base types, objects, lists, non-nulls)
- Which parameters (filters) are available when asking for a field
- Mutations (intended to change data)
- Deprecation warnings
- Additional metadata (descriptions, examples)
Usage
Basically, GraphQL is invoked over an HTTP client, like most of the APIs today. In the route you need to target the root path of GraphQL service. In the body a request query or mutation should be sent with optional variables section. The format of the request is a GraphQL request syntax and is a standard. Once the request is executed, in the response you can expect a JSON with two main sub-sections: data and errors.
GraphQL does not return HTTP status codes to indicate specific error cases. It always returns a 200 OK status, and notifies the client of any specific errors in the errors section. This enables the request to be partially successfully executed (such as when user is not authorized for parts of the query).
Since GraphQL is a mature technology, there’s a plenty of implementations/libraries for various languages and backends, frontends, and even mobile devices.
For .NET, our recommended libraries are HotChocolate or GraphQL-dotnet:
For Java, we’d recommend folks to check out GraphQL Java:
When it comes to mobile development, we found plenty of libraries but like Apollo:
When developing against a GraphQL server, it is convenient to be able to try it out, before coding. Tools mostly used for this are: GraphQL Playground, Postman, GraphiQL and Insomnia.
GraphQL is not a silver bullet for system architecture challenges. It is well designed to offer a façade for clients, but it does not imply the backend implementation. It can have an array of micro-services, different storages or a cache as a backend. It is also able to expose a combination of different sources without leaking their implementation. Because of its core feature of aggregation, it is behaving more like a monolithic gateway to the system. While libraries for certain sources already exist, it is very easy to provide a source of your own.
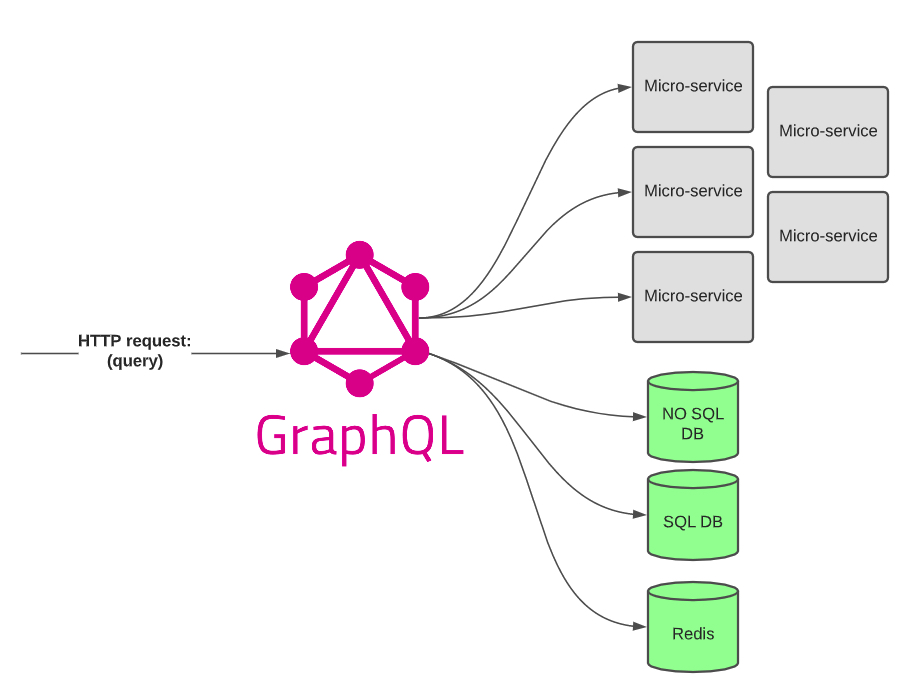
GraphQL at Redbox
At Redbox we use it to provide a façade over a cluster of micro-services with different contracts and organizing resources together even if they’re in several different micro-services or external systems.
It was initially built to replace On Demand backend APIs exposing several domains such as device management, product info, playback streams/progress, and many other core features of a typical streaming platform. Overtime, GraphQL popularity internally grew to exposes additional domains like Redbox Perks, Kiosk services (such as inventory, reservation, and pricing), and even some internal transactional services!
GraphQL allows us to expose parts of the schema publicly such as product metadata or pricing, while enabling us to protect other parts with more restrictions by user/application.
Redbox has the mentality of using the right tool for the job. In addition, we empower our engineers to pick the right tools they need to build their applications. As a result, some of our infrastructure resides in various cloud providers. It enables us integrate with our vast infrastructure seamlessly. Whether we are running in a Multi-Region Google Cloud GKE Cluster, behind an ELB in AWS, or even a legacy datacenter, GraphQL enables us to seamless stitch together a consistent response from various complex sources. GraphQL also uses some data storage services directly like Google Cloud Firestore and uses event infrastructure like Google Cloud’s PubSub.
In backend, we use ChilliCream’s HotChocolate GraphQL library that has proven itself as scalable, stable, and extensible solution — shout out to the awesome folks at ChilliCream! On the client side, we use URQL for most front-end clients with Apollo for our mobile clients. While GraphQL can be called from clients with a simple HTTP client, libraries help manage payloads, error handling and versioning better. Thanks everyone who supports, builds, and maintains these platforms/libraries!
We track performance of GraphQL with real-time metrics implemented with Prometheus and Grafana. These metrics are scoped to all fields, as well as usual queries and deprecated fields. Longer-living event metrics are available through sending events to Google Cloud’s BigQuery.
Benefits
With GraphQL in place for OnDemand and Physical, we already reaped several of the general benefits of GraphQL.
With contracts where clients are able to pick-and-choose, mobile, TV clients and web are executing slightly different requests against the GraphQL and have already changed their requests few times. All that without GraphQL contracts being changed, and all the time with minimal response sizes needed.
With GraphQL in place, our backend was able to evolve and crank things up to 11. As a result, several internal dependencies were able to be changed as part of our digital transformation efforts as well! We were able to scale and modify our personalization services to separate and distinct micro-services; breaking legacy monolithic applications.
Redbox has been around for many years and as a result has a large application platform it supports for both Physical Kiosks as well as On Demand. By leveraging GraphQL, we were able to migrate a legacy monolithic service for our Kiosk as well to our new micro-services architecture; improving their data, better inventory, and faster pricing updates. All these features/improvements were released in a way that did not impact our users; which is our goal above all else.
There are many other improvements that GraphQL offered us but we will aim to cover in other articles soon! In addition, we aim to cover not only how we use GraphQL but some of our learnings, success/failure stories, and much more. In addition to this, we hope to cover our software delivery processes that enable developers to build, test, deploy, and maintain their own code with a click of a button in future articles as well!
Come work with Redbox!
Migrating and building a cloud native tech stack is tough! We are always looking for more talented engineers to help us build and grow! If you’re interested in having a lot of autonomy and opportunity to solve complex problems at scale, take a gander at our Engineering job postings!
Written by Marko Lazic, Team Lead at Redbox LLC. The original blog post is published on Medium.




